



Download Now
O'Reilly's Book "Building ML Systems" First Chapter Available!



A feature store is a central vault for storing documented, curated, and access-controlled features. In this blog post, we discuss the state-of-the-art in data management for deep learning and present the first open-source feature store, available in Hopsworks.
The concept of a feature store was introduced by Uber in 2017. The feature store is a central place to store curated features within an organization. A feature is a measurable property of some data-sample.
It could be for example an image-pixel, a word from a piece of text, the age of a person, a coordinate emitted from a sensor, or an aggregate value like the average number of purchases within the last hour. Features can be extracted directly from files and database tables, or can be derived values, computed from one or more data sources.
Features are the fuel for AI systems, as we use them to train machine learning models so that we can make predictions for feature values that we have never seen before.

Writing to the feature store: The interface for Data Engineers. At the end of the feature engineering pipeline, instead of writing features to a file or a project-specific database or file, features are written to the feature store.

Reading from the feature store:
The interface for Data Scientists. To train a model on a set of features, the features can be read from the feature store directly.

A feature store is not a simple data storage service, it is also a data transformation service as it makes feature engineering a first-class construct. Feature engineering is the process of transforming raw data into a format that is understandable for predictive models.
At Hopsworks we are committed to developing technologies to operate machine learning workflows at large scale and to help organizations distill intelligence from data. Machine learning is an extremely powerful method that has the potential to help us move from a historical understanding of the world to a predictive modeling of the world around us. However, building machine learning systems is hard and requires specialized platforms and tools.
Although ad-hoc feature engineering and training pipelines is a quick way for Data Scientists to experiment with machine learning models, such pipelines have a tendency to become complex over time.
As the number of models increases, it quickly becomes a pipeline jungle that is hard to manage. This motivates the usage of standardized methods and tools for the feature engineering process, helping reduce the cost of developing new predictive models. The feature store is a service designed for this purpose.
“Machine Learning: The High-Interest Credit Card of Technical Debt”
Machine learning systems have a tendency to assemble technical debt [1]. Examples of technical debt in machine learning systems are:
Several organizations that we have spoken to struggle to scale their machine learning workflows due to the technical complexity, and some teams are even reluctant to adopt machine learning considering the high technical cost of it.
Using a feature store is a best practice for an MLOps pipeline, it can reduce the technical debt of machine learning workflows.
“Pipeline jungles can only be avoided by thinking holistically about data collection and feature extraction”
“Data is the hardest part of ML and the most important piece to get right. Modelers spend most of their time selecting and transforming features at training time and then building the pipelines to deliver those features to production models. Broken data is the most common cause of problems in production ML systems”
– Uber [2]
Delivering machine learning solutions in production and at large-scale is very different from fitting a model to a pre-processed dataset. In practice, a large part of the effort that goes into developing a model is spent on feature engineering and data wrangling.

There are many different ways to extract features from raw data, but common feature engineering steps include:
To illustrate the importance of feature engineering, let’s consider a classification task on a dataset with just one feature, x1, that looks like this:

We are doomed to fail if we try to fit a linear model directly to this dataset as it is not linearly separable. During feature engineering we can extract an additional feature, x2, where the function for deriving x2from the raw dataset is x2 = (x1)^2. The resulting two-dimensional dataset might look like depicted in Figure 2.

By adding an extra feature, the dataset becomes linearly separable and can be fitted by our model. This was a simple example, in practice the process of feature engineering can involve much more complex transformations.
In the case of deep learning, deep models tend to perform better the more data they are trained on (more data samples during training can have a regularizing effect and combat overfitting). Consequently, a trend in machine learning is to train on increasingly larger datasets.
This trend further complicates the feature engineering process as Data Engineers must think about scalability and efficiency in addition to the feature engineering logic. With a standardized and scalable feature platform, the complexity of feature engineering can be managed more effectively.

In Figure 5, feature code is duplicated across training jobs and there are also features that have different implementations: one for training, and one for deployment (Inferencing) (Model C). Having different implementations for computing features for training and deployment entails non-DRY code and can lead to prediction problems.
Moreover, without a feature store, features are typically not reusable as they are embedded in training/serving jobs. This also means that Data Scientists have to write low level code for accessing data stores, requiring data engineering skills. There is also no service to search for feature implementations, and there is no management or governance of features.

Data Scientists can now search for features, and with API support, easily use them to build models with minimal data engineering. In addition, features can be cached and reused by other models, reducing model training time and infrastructure costs. Features are now a managed, governed asset in the Enterprise.
A frequent pitfall for organizations that apply machine learning is to think of data science teams as individual groups that work independently with limited collaboration. Having this mindset results in machine learning workflows where there is no standardized way to share features across different teams and machine learning models.
Not being able to share features across models and teams is limiting Data Scientist's productivity and makes it harder to build new models. By using a shared feature store, organizations can achieve an economies-of-scale effect. When the feature store is built up with more features, it becomes easier and cheaper to build new models as the new models can re-use features that exist in the feature store.

During 2018, a number of large companies that are at the forefront of applying machine learning at scale announced the development of proprietary feature stores. Uber, LinkedIn, and Airbnb built their feature stores on Hadoop data lakes, while Comcast built a feature store on an AWS data lake, and GO-JEK built a feature store on Google’s data platform.
Before we dive into the feature store API and its usage, let’s have a look at the technology stack that we built our feature store on.
The architecture of the feature store is depicted in Figure 8.

At Hopsworks we specialize in Python-first ML pipelines, and for feature engineering we focus our support on Spark, PySpark, Numpy, and Pandas. The motivation for using Spark/PySpark to do feature engineering is that it is the preferred choice for data wrangling among our users that are working with large-scale datasets.
However, we have also observed that users working with small datasets prefer to do the feature engineering with frameworks such as Numpy and Pandas, which is why we decided to provide native support for those frameworks as well. Users can submit feature engineering jobs on the Hopsworks platform using notebooks, python files, or .jar files.
We have built the storage layer for the feature data on top of Hive/HopsFS with additional abstractions for modeling feature data.
The reason for using Hive as the underlying storage layer is two-fold: (1) it is not uncommon that our users are working with datasets in terabyte-scale or larger, demanding scalable solutions that can be deployed on HopsFS (see blog post on HopsFS [9]); and (2) data modeling of features is naturally done in a relational manner, grouping relational features into tables and using SQL to query the feature store.
This type of data modelling and access patterns fits well with Hive in combination with columnar storage formats such as Parquet or ORC.
To provide automatic versioning, documentation, feature analysis, and feature sharing we store extended metadata about features in a metadata store. For the metadata store we utilize NDB (MySQL Cluster) which allows us to keep feature metadata that is strongly consistent with other metadata in Hopsworks, such as metadata about feature engineering jobs and datasets.
We introduce three new concepts to our users for modeling data in the feature store.

When designing feature groups, it is a best-practice to let all features that are computed from the same raw datasets to be in the same feature group. It is common that there are several feature groups that share a common column, such as a timestamp or a customer-id, that allows feature groups to be joined together into a training dataset.
The feature store has two interfaces; one interface for writing curated features to the feature store and one interface for reading features from the feature store to use for training or serving.
The feature store is agnostic to the method for computing the features. The only requirement is that the features can be grouped together in a Pandas, Numpy, or Spark dataframe. The user provides a dataframe with features and associated feature metadata (metadata can also be edited later through the feature registry UI) and the feature store library takes care of creating a new version of the feature group, computing feature statistics, and linking the features to the job to compute them.

To read features from the feature store, users can use either SQL or APIs in Python and Scala. Based on our experience with users on our platform, Data Scientists can have diverse backgrounds. Although some Data Scientists are very comfortable with SQL, others prefer higher level APIs.
This motivated us to develop a query-planner to simplify user queries. The query-planner enables users to express the bare minimum information to fetch features from the feature store.
For example, a user can request 100 features that are spread across 20 different feature groups by just providing a list of feature names. The query-planner uses the metadata in the feature store to infer where to fetch the features from and how to join them together.

To fetch the features “average_attendance” and “average_player_age” from the feature store, all the user has to write is this.

The returned “features_df” is a (Pandas, Numpy, or Spark) dataframe that can then be used to generate training datasets for models.
Organizations typically have many different types of raw datasets that can be used to extract features. For example, in the context of user recommendation there might be one dataset with demographic data of users and another dataset with user activities. Features from the same dataset are naturally grouped into a feature group, and it is common to generate one feature group per dataset.
When training a model, you want to include all features that have predictive power for the prediction task, these features can potentially span multiple feature groups. The training dataset abstraction in the Hopsworks Feature Store is used for this purpose. The training dataset allows users to group a set of features with labels for training a model to do a particular prediction task.
Once a user has fetched a set of features from different feature groups in the feature store, the features can be joined with labels (in case of supervised learning) and materialized into a training dataset.
By creating a training dataset using the feature store API, the dataset becomes managed by the feature store. Managed training datasets are automatically analyzed for data anomalies, versioned, documented, and shared with the organization.

To create a managed training dataset, the user supplies a Pandas, Numpy or Spark dataframe with features, labels, and metadata.

Once the training dataset has been created, the dataset is discoverable in the feature registry and users can use it to train models. Below is an example code snippet for training a model using a training dataset stored in a distributed manner in the tfrecords format on HopsFS.

The feature registry is the user interface for publishing and discovering features and training datasets. The feature registry also serves as a tool for analyzing feature evolution over time by comparing feature versions. When a new data science project is started, Data Scientists within the project typically begin by scanning the feature registry for available features, and only add new features for their model that do not already exist in the feature store.

The feature registry provides :
When a feature group or training dataset is updated in the feature store, a data analysis step is performed. In particular, we look at cluster analysis, feature correlation, feature histograms, and descriptive statistics.
We have found that these are the most common type of statistics that our users find useful in the feature modeling phase. For example, feature correlation information can be used to identify redundant features, feature histograms can be used to monitor feature distributions between different versions of a feature to discover covariate shift, and cluster analysis can be used to spot outliers. Having such statistics accessible in the feature registry helps users decide on which features to use.


When the feature store increases in size, the process of scheduling jobs to recompute features should be automated to avoid a potential management bottleneck. Feature groups and training datasets in Hopsworks feature store are linked to Spark/Numpy/Pandas jobs which enables the reproduction and recompution of the features when necessary.
Moreover, each feature group and training dataset can have a set of data dependencies. By linking feature groups and training datasets to jobs and data dependencies, the features in the Hopsworks feature store can be automatically backfilled using workflow management systems such as Airflow [10].
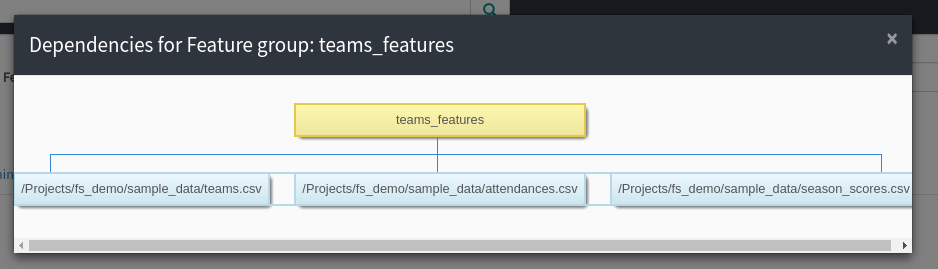
We believe that the biggest benefit of a feature store comes when it is centralized across the entire organization. The more high-quality features available in the feature store the better. For example, in 2017 Uber reported that they had approximately 10000 features in their feature store [11].
Despite the benefit of centralizing features, we have identified a need to enforce access control to features. Several organizations that we have talked to are working partially with sensitive data that requires specific access rights that is not granted to everyone in the organization. For example, it might not be feasible to publish features that are extracted from sensitive data to a feature store that is public within the organization.
To solve this problem we utilize the multi-tenancy property built-in to the architecture of the Hopsworks platform [12]. Feature stores in Hopsworks are by default project-private and can be shared across projects, which means that an organization can combine public and private feature stores. An organization can have a central public feature store that is shared with everyone in the organization as well as private feature stores containing features of sensitive nature that are only accessible by users with the appropriate permissions.

The feature store covered in this blog post is a so called batch feature store, meaning that it is a feature store designed for training and non-real time model serving. In future work, we plan to extend the feature store to meet real-time guarantees that are required during serving of user-facing models.
Moreover, we are currently in the process of evaluating the need for a Domain Specific Language (DSL) for feature engineering. By using a DSL, users that are not proficient in Spark/Pandas/Numpy can provide an abstract declarative description of how features should be extracted from raw data and then the library translates that description into a Spark job for computing the features.
Finally, we are also looking into supporting Petastorm [13] as a data format for training datasets. By storing training datasets in Petastorm we can feed Parquet data directly into machine learning models in an efficient manner. We consider Petastorm as a potential replacement for tfrecords, that can make it easier to re-use training datasets for other ML-frameworks than Tensorflow, such as PyTorch.
Building successful AI systems is hard. At Hopsworks we have observed that our users spend a lot of effort on the Data Engineering phase of machine learning. From the release of version 0.8.0, Hopsworks provides the world’s first open-source feature store. A feature store is a data management layer for machine learning that allows Data Scientists and Data Engineers to share and discover features, better understand features over time, and effectivize the machine learning workflow.
This article was first published on December 30th 2018, updated on February 2nd 2023.
[1] Hidden Technical Debt in Machine Learning Systems: https://papers.nips.cc/paper/5656-hidden-technical-debt-in-machine-learning-systems.pdf
[2] Scaling Machine Learning at Uber with Michelangelo: https://eng.uber.com/scaling-michelangelo/
[3] Machine Learning: The High-Interest Credit Card of Technical Debt: https://static.googleusercontent.com/media/research.google.com/sv//pubs/archive/43146.pdf
[4] Scaling Machine Learning as a Service (Uber): http://proceedings.mlr.press/v67/li17a/li17a.pdf
[5] Zipline: Airbnb’s Machine Learning Data Management Platform: https://databricks.com/session/zipline-airbnbs-machine-learning-data-management-platform
[6] Operationalizing Machine Learning—Managing Provenance from Raw Data to Predictions: https://databricks.com/session/operationalizing-machine-learning-managing-provenance-from-raw-data-to-predictions
[7] Building a Feature Platform to Scale Machine Learning | DataEngConf BCN '18: https://www.youtube.com/watch?v=0iCXY6VnpCc
[8] HopsML, Python-First ML Pipelines
[9] Fixing the Small Files Problem in HDFS: https://www.logicalclocks.com/fixing-the-small-files-problem-in-hdfs/
[10] Airflow: https://airflow.apache.org/
[11] Meet Michelangelo: Uber’s Machine Learning Platform: https://eng.uber.com/michelangelo/
[12] Introducing Hopsworks: https://www.logicalclocks.com/introducing-hopsworks/
[13] Petastorm: https://github.com/uber/petastorm
[14] Deep learning scaling is predictable, empirically: https://blog.acolyer.org/2018/03/28/deep-learning-scaling-is-predictable-empirically/
[15] Feature Store at LinkedIn https://www.thestrangeloop.com/2018/democratizing-ai—back-fitting-end-to-end-machine-learning-at-linkedin-scale.html


© Hopsworks 2024. All rights reserved. Various trademarks held by their respective owners.


