



Download Now
O'Reilly's Book "Building ML Systems" First Chapter Available!



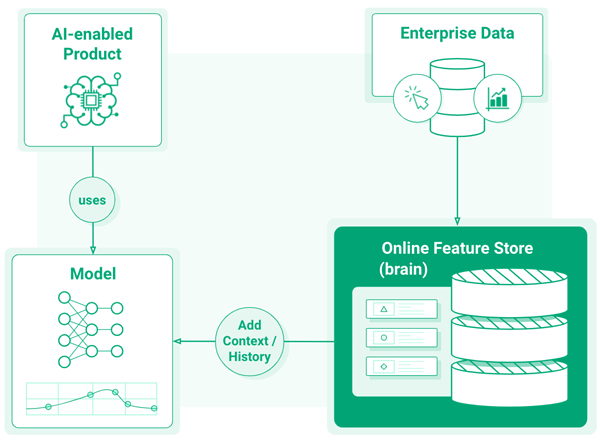
Machine learning models are only as good as the data (features) they are trained on. In Enterprises, data scientists can often train very effective models in the lab - when given a free hand on which data to use. However, many of those data sources are not available in production environments due to disconnected systems and data silos. An AI-powered product that is limited to the data available within its application silo cannot recall historical data about its users or relevant contextual data from external sources. It is like a jellyfish - its autonomic system makes it functional and useful, but it lacks a brain. You can, however, evolve your models from brain-free AI to Total Recall AI with the help of a Feature Store, a centralized platform that can provide models with low latency access to data spanning the whole enterprise.

Jellyfish are undoubtedly complex creatures with sophisticated behaviour - they move, mate, and munch. They eat and discard waste from the same opening. Yet they have no brain - their autonomic system suffices for their needs. The biggest breakthroughs in AI in recent years have been enabled by deep learning, which requires large volumes of data and specialized compute hardware (e.g., GPUs). However, just like a jellyfish, recent successes in image processing and NLP with deep learning required no brain - no working memory, history, or context. Much of deep learning today is Jellyfish AI. We have made incredible progress in identifying objects in images and translating natural language, yet such deep learning models typically only require the immediate input - the image or the text - to make their predictions. The input signal is information-rich. These image and NLP models seldom require a 'brain' to augment the input with context or memories. Google translate doesn’t need to know the historical enmity between the Scots and the Irish in whether its spelt Whisky or Whiskey. Jellyfish AI is impressive - the input data is information rich and models can learn fantastically advanced behaviour from labeled examples. All “knowledge” needed to make predictions is embedded in the model. The model does not need to have working memory (e.g., it doesn’t need to know the user has clicked 10 times on your website in the last minute).
Now compare using AI for image classification or NLP to building a web application that will use AI to interact with a user browsing a website. The immediate input data your application receives from your web browser are clicks on a mouse or a keyboard. The input signal is information-light - it is difficult to train a useful model using only user clicks. However, large Internet companies collect reams of information about users from many different sources, and transform that user data into features (information-rich signals that are ready to be used for either training models or making predictions with models). Models can then combine the click features with historical features about users and contextual features to build information-rich inputs to models. For example, you could augment the user’s action with everything you know about a user’s history and context to increase the user's engagement with the product. The feature store for machine learning (ML) stores and serves these features to models. We believe that AI-powered products that can easily access historical and contextual features will lead the next wave of AI in the Enterprise, and those products will need a feature store for ML.
A frequent source of tension in Enterprises is between “naive” data scientists and “street-wise” ML engineers. Motivated by good software engineering practices, many ML engineers believe that ML models should be self-contained and tension can arise with data scientists who want to include features in their models that are “obviously not available in the production system”.
However, data scientists are tasked with building the best models they can to add to the bottom line - engage more users, increase revenue, reduce costs. They know they can train better models with more data and more diverse sources of data. For example, a data scientist trying to predict if a financial transaction is suspected of money laundering or not might discover that a powerful feature is the graph of financial transfers related to this individual in the previous day/week/month. They can reduce false alerts of money launder by a factor of 100*, reducing the costs of investigating the false alerts, saving the business millions of dollars per year. The data scientist hands the model over the wall to the ML engineer who dismisses the idea of including the graph-based features in the production environment, and tension arises when communicating what is possible and what is not possible in production. The data scientist is crestfallen - but need not be.
The Feature Store is now the de facto Enterprise platform for storing historical and contextual features for AI-powered products. The Feature Store is, in effect, the brain for AI-powered products, the three-eyed Raven that enables the model to access the history and state of the whole Enterprise, not just the local state in the application.
Feature Stores enable applications or model serving infrastructure to take information-light inputs (such as a cookie identifying a user or a shopping cart session) and enrich it with features harvested from anywhere in the Enterprise or beyond to build feature vectors capable of making better predictions. And as we know from Deep Learning, model accuracy improves predictably with more features and data, so there will be an increasing trend towards adding more and more features to models to improve their accuracy. Andrew Ng has recently been advocating this approach that he calls data-centric development, instead of the more traditional model-centric development. Another noticeable trend in large Enterprises is building faster and more scalable Feature stores that can supply those features within the time budget available to the AI-powered product. But AI is going to revolutionize Enterprise software products, so how do we make sure our AI-enabled products are not just Jellyfish AI?

How do we avoid limiting AI-enabled products to only using the input features collected by the application itself? Models will benefit from access to all data that the Enterprise has collected about the user, product, or its context. A potential source of friction here, however, is the dominant architectural preference for microservices and data stove-pipes. Models themselves are being deployed as microservices in model-serving infrastructure, like KFServing or TensorFlow Serving or Nvidia Triton. How can we give these models access to more features?

Without a Feature Store, applications could contact microservices or databases to compute or retrieve the historical and contextual features (data), respectively. Computing the features in the application itself is an anti-pattern as it duplicates the feature engineering code - that code should already exist to generate the training data for the model. Re-implementing feature engineering logic in applications also introduces the risk of skew between the features computed in the application and the features computed for training. If serving and training environments use the same programming language, they could avoid non-DRY code by reusing a versioned library that computes the features. However, even if feature engineering logic is written in Python in both training and serving, it may use PySpark for training and Python for serving or different versions of Python. Versioned libraries can help, but are not a general solution to the feature skew problem.
The Feature Store solves the training/serving skew problem by computing the features once in a feature pipeline. The feature pipeline is then reused to (1) create training data, and (2) save those pre-engineered features to the Feature Store. The serving infrastructure can then retrieve those features when needed to make predictions. For example, when an application wants to make a prediction about a user, it would supply the user’s ID, shopping cart ID, session ID, or location to retrieve pre-engineered features from the Feature Store. The features are retrieved as a feature vector, and the feature vector is sent to the model that makes the prediction. The Feature Store service for retrieving feature vectors is commonly known as the Online Feature Store. The logic for retrieving features from the Online Feature Store can also be implemented in model serving infrastructure, not just in applications. The advantage of looking up features in serving infrastructure is that it keeps the application logic cleaner, and the application just sends IDs and real-time features to the model serving infrastructure, that in turn, builds the feature vector, sends it to the model for prediction, and returns the result to the application. Low latency and high throughput are important properties for the online feature store - the faster you can retrieve features and the more features you can include in a given time budget, the more accurate models you should be able to deploy in production. To quote DoorDash:
“Latency on feature stores is a part of model serving, and model serving latencies tend to be in the low milliseconds range. Thus, read latency has to be proportionately lower”
So, to summarize, if you want to give your ML models a brain, connect them up to a feature store. For Enterprises building personalized services, the featurestore can enrich their models with a 360 degree Enterprise wide view of the customer - not just a product-specific view of the customer. The feature store enables more accurate predictions through more data being available to make those predictions, and this ultimately enables products with better user experience, increased engagement, and the product intelligence now expected by users.
* This is based on a true story.


© Hopsworks 2024. All rights reserved. Various trademarks held by their respective owners.


